2.1 Understanding word embeddings
2.2 Tokenizing text
2.3 Converting tokens into token IDs
2.4 Adding special context tokens
2.5 Byte pair encoding
2.6 Data sampling with a sliding window
The previous section covered the tokenization steps and conversion from string tokens into integer token IDs in great detail. The next step before we can finally create the embeddings for the LLM is to generate the input-target pairs required for training an LLM.
前一节详细介绍了分词步骤和将字符串词元转换为整数词元ID的过程。在最终为LLM创建嵌入之前,下一步是生成训练LLM所需的输入-目标对。
What do these input-target pairs look like? As we learned in chapter 1, LLMs are pretrained by predicting the next word in a text, as depicted in figure 2.12.
这些输入-目标对是什么样的?正如我们在第1章中学到的,LLM通过预测文本中的下一个单词进行预训练,如图2.12所示。
Figure 2.12 Given a text sample, extract input blocks as subsamples that serve as input to the LLM, and the LLM’s prediction task during training is to predict the next word that follows the input block. During training, we mask out all words that are past the target. Note that the text shown in this figure would undergo tokenization before the LLM can process it; however, this figure omits the tokenization step for clarity.
图2.12 给定一个文本样本,提取输入块作为子样本,作为LLM的输入,LLM在训练期间的预测任务是预测紧跟在输入块后的下一个单词。在训练期间,我们屏蔽了所有超出目标的单词。请注意,图中显示的文本在LLM处理之前会进行分词;然而,为了清晰起见,本图省略了分词步骤。
In this section we implement a data loader that fetches the input-target pairs depicted in Figure 2.12 from the training dataset using a sliding window approach.
在本节中,我们实现了一个数据加载器,该加载器使用滑动窗口方法从训练数据集中获取图2.12中描绘的输入-目标对。
To get started, we will first tokenize the whole The Verdict short story we worked with earlier using the BPE tokenizer introduced in the previous section:
首先,我们将使用上一节介绍的BPE分词器对整个The Verdict短篇小说进行分词:
1 | with open("the-verdict.txt", "r", encoding="utf-8") as f: # 打开文本文件 |
Executing the code above will return 5145, the total number of tokens in the training set, after applying the BPE tokenizer.
执行上述代码将返回5145,这是应用BPE分词器后的训练集中词元的总数量。
Next, we remove the first 50 tokens from the dataset for demonstration purposes as it results in a slightly more interesting text passage in the next steps:
接下来,我们从数据集中移除前50个词元以进行演示,因为这会在接下来的步骤中生成一个稍微有趣的文本段落:
1 | enc_sample = enc_text[50:] # 移除前50个词元 |
One of the easiest and most intuitive ways to create the input-target pairs for the next-word prediction task is to create two variables, x and y, where x contains the input tokens and y contains the targets, which are the inputs shifted by 1:
创建输入-目标对进行下一个单词预测任务的最简单和最直观的方法之一是创建两个变量,x 和 y,其中 x 包含输入词元,y 包含目标,即输入右移1位:
1 | context_size = 4 # 上下文大小确定输入中包含的词元数量 #A |
Running the above code prints the following output:
运行上述代码打印以下输出:
1 | x: [290, 4920, 2241, 287] |
Processing the inputs along with the targets, which are the inputs shifted by one position, we can then create the next-word prediction tasks depicted earlier in figure 2.12, as follows:
处理包含目标的输入,目标是输入右移一个位置,然后我们可以创建图2.12中所描绘的下一个单词预测任务,如下所示:
1 | for i in range(1, context_size+1): # 遍历上下文大小 |
The code above prints the following:
上述代码打印以下内容:
1 | [290] ----> 4920 |
Everything left of the arrow (—->) refers to the input an LLM would receive, and the token ID on the right side of the arrow represents the target token ID that the LLM is supposed to predict.
箭头(—->)左边的所有内容表示LLM将接收的输入,箭头右边的词元ID表示LLM应预测的目标词元ID。
For illustration purposes, let’s repeat the previous code but convert the token IDs into text:
为了说明,我们重复前面的代码,但将词元ID转换为文本:
1 | for i in range(1, context_size+1): # 遍历上下文大小 |
The following outputs show how the input and outputs look in text format:
下面的输出显示了输入和输出在文本格式中的样子:
1 | and ----> established |
We’ve now created the input-target pairs that we can turn into use for the LLM training in upcoming chapters.
我们现在已经创建了输入-目标对,可以将它们用于LLM训练。
There’s only one more task before we can turn the tokens into embeddings, as we mentioned at the beginning of this chapter: implementing an efficient data loader that iterates over the input dataset and returns the inputs and targets as PyTorch tensors, which can be thought of as multidimensional arrays.
在我们将词元转换为嵌入之前,还有最后一个任务:实现一个高效的数据加载器,它遍历输入数据集并将输入和目标作为PyTorch张量返回,可以将其视为多维数组。
In particular, we are interested in returning two tensors: an input tensor containing the text that the LLM sees and a target tensor that includes the targets for the LLM to predict, as depicted in Figure 2.13.
特别是,我们希望返回两个张量:一个包含LLM看到的文本的输入张量,另一个包含LLM要预测的目标的目标张量,如图2.13所示。
Figure 2.13 To implement efficient data loaders, we collect the inputs in a tensor, x, where each row represents one input context. A second tensor, y, contains the corresponding prediction targets (next words), which are created by shifting the input by one position.
图2.13 为了实现高效的数据加载器,我们将输入收集到一个张量x中,每行表示一个输入上下文。第二个张量y包含相应的预测目标(下一个单词),通过将输入右移一个位置创建。
While Figure 2.13 shows the tokens in string format for illustration purposes, the code implementation will operate on token IDs directly since the encode method of the BPE tokenizer performs both tokenization and conversion into token IDs as a single step.
虽然图2.13出于说明目的以字符串格式显示词元,但代码实现将直接对词元ID进行操作,因为BPE分词器的编码方法将分词和转换为词元ID作为一个步骤执行。
For the efficient data loader implementation, we will use PyTorch’s built-in Dataset and DataLoader classes. For additional information and guidance on installing PyTorch, please see section A.1.3, Installing PyTorch, in Appendix A.
为了实现高效的数据加载器,我们将使用PyTorch的内置Dataset和DataLoader类。有关安装PyTorch的更多信息和指导,请参见附录A的A.1.3节“安装PyTorch”。
Listing 2.5 A dataset for batched inputs and targets
清单2.5 用于批处理输入和目标的数据集
1 | import torch # 导入torch |
The GPTDatasetV1 class in listing 2.5 is based on the PyTorch Dataset class and defines how individual rows are fetched from the dataset, where each row consists of a number of token IDs (based on a max_length) assigned to an input_chunk tensor. The target_chunk tensor contains the corresponding targets. I recommend reading on to see how the data returned from this dataset looks like when we combine the dataset with a PyTorch DataLoader – this will bring additional intuition and clarity.
清单2.5中的GPTDatasetV1类基于PyTorch的Dataset类,定义了如何从数据集中获取单个行,其中每行由分配给input_chunk张量的一定数量的词元ID(基于max_length)组成。target_chunk张量包含相应的目标。我建议继续阅读以了解当我们将数据集与PyTorch的DataLoader结合使用时,从该数据集中返回的数据是什么样子的,这将带来更多的直观理解和清晰度。
If you are new to the structure of PyTorch Dataset classes, such as shown in listing 2.5, please read section A.6, Setting up efficient data loaders, in Appendix A, which explains the general structure and usage of PyTorch Dataset and DataLoader classes.
如果你不熟悉PyTorch的Dataset类的结构,如清单2.5所示,请阅读附录A的A.6节“设置高效的数据加载器”,其中解释了PyTorch的Dataset和DataLoader类的一般结构和用法。
The following code will use the GPTDatasetV1 to load the inputs in batches via a PyTorch DataLoader:
以下代码将使用GPTDatasetV1通过PyTorch的DataLoader按批次加载输入:
Listing 2.6 A data loader to generate batches with input-with pairs
清单2.6 一个用于生成输入-目标对批处理的数据加载器
1 | def create_dataloader_v1(txt, batch_size=4, max_length=256, # 创建数据加载器 |
Let’s test the dataloader with a batch size of 1 for an LLM with a context size of 4 to develop an intuition of how the GPTDatasetV1 class from listing 2.5 and the create_dataloader_v1 function from listing 2.6 work together:
让我们使用批次大小为1的数据加载器来测试具有上下文大小为4的LLM,以了解清单2.5中的GPTDatasetV1类和清单2.6中的create_dataloader_v1函数如何协同工作:
1 | with open("the-verdict.txt", "r", encoding="utf-8") as f: # 打开文本文件 |
Executing the preceding code prints the following:
执行上述代码打印以下内容:
1 | (tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])) |
The first_batch variable contains two tensors: the first tensor stores the input token IDs, and the second tensor stores the target token IDs. Since the max_length is set to 4, each of the two tensors contains 4 token IDs. Note that an input size of 4 is relatively small and only chosen for illustration purposes. It is common to train LLMs with input sizes of at least 256.
first_batch变量包含两个张量:第一个张量存储输入词元ID,第二个张量存储目标词元ID。由于max_length设置为4,每个张量包含4个词元ID。请注意,4的输入大小相对较小,仅用于说明目的。训练LLM时通常使用至少256的输入大小。
To illustrate the meaning of stride=1, let’s fetch another batch from this dataset:
为了说明stride=1的含义,让我们从这个数据集中获取另一个批次:
1 | second_batch = next(data_iter) # 获取下一个批次的数据 |
The second batch has the following contents:
第二个批次包含以下内容:
1 | (tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])) |
If we compare the first with the second batch, we can see that the second batch’s token IDs are shifted by one position compared to the first batch (for example, the second ID in the first batch’s input is 367, which is the first ID of the second batch’s input). The stride setting dictates the number of positions the inputs shift across batches, emulating a sliding window approach, as demonstrated in Figure 2.14.
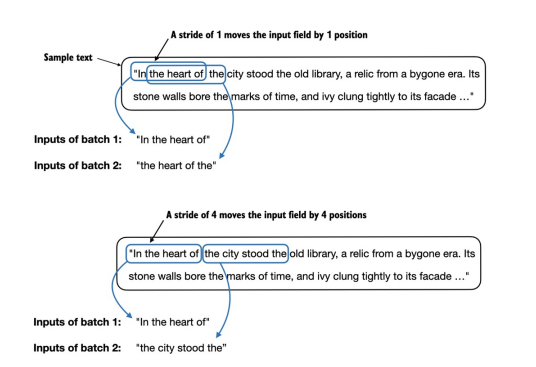
如果我们将第一个批次与第二个批次进行比较,可以看到第二个批次的词元ID与第一个批次相比右移了一个位置(例如,第一个批次输入的第二个ID是367,这是第二个批次输入的第一个ID)。stride设置决定了输入在批次之间移动的位置数,模拟滑动窗口方法,如图2.14所示。
Figure 2.14 When creating multiple batches from the input dataset, we slide an input window across the text. If the stride is set to 1, we shift the input window by 1 position when creating the next batch. If we set the stride equal to the input window size, we can prevent overlaps between the batches.
图2.14 当从输入数据集创建多个批次时,我们在文本中滑动输入窗口。如果stride设置为1,则在创建下一个批次时将输入窗口右移1个位置。如果我们将stride设置为等于输入窗口大小,可以防止批次之间的重叠。
EXERCISE 2.2 DATA LOADERS WITH DIFFERENT STRIDES AND CONTEXT SIZES
练习 2.2 具有不同stride和context大小的数据加载器
To develop more intuition for how the data loader works, try to run it with different settings such as max_length=2 and stride=2 and max_length=8 and stride=2.
为了更好地理解数据加载器的工作原理,请尝试使用不同的设置运行它,例如max_length=2和stride=2以及max_length=8和stride=2。
Batch sizes of 1, such as we have sampled from the data loader so far, are useful for illustration purposes. If you have previous experience with deep learning, you may know that small batch sizes require less memory during training but lead to more noisy model updates. Just like in regular deep learning, the batch size is a trade-off and hyperparameter to experiment with when training LLMs.
批次大小为1,如我们迄今从数据加载器中采样的那些,非常适合作为说明。如果你有深度学习的经验,你可能知道小批次大小在训练期间需要更少的内存,但会导致更噪声的模型更新。就像在常规深度学习中一样,批次大小是一种权衡和超参数,在训练LLM时需要进行实验。
Before we move on to the two final sections of this chapter that are focused on creating the embedding vectors from the token IDs, let’s have a brief look at how
we can use the data loader to sample with a batch size greater than 1:
在我们进入本章的最后两个部分之前,这两个部分重点是从词元ID创建嵌入向量,让我们简要了解如何使用数据加载器以大于1的批次大小进行采样:
1 | dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4) |
Note that we increase the stride to 4. This is to utilize the data set fully (we don’t skip a single word) but also avoid any overlap between the batches, since more overlap could lead to increased overfitting.
注意,我们将步幅增加到4。这是为了充分利用数据集(我们不会跳过一个单词),但也避免了批次之间的任何重叠,因为更多的重叠可能导致过拟合的增加。
In the final two sections of this chapter, we will implement embedding layers that convert the token IDs into continuous vector representations, which serve as input data format for LLMs.
在本章的最后两节中,我们将实现嵌入层,将词元ID转换为连续的向量表示,作为LLM的输入数据格式。