Array.prototype.myMap = function(callback) { const result = []; for (let i = 0; i < this.length; i++) { if (this.hasOwnProperty(i)) { result.push(callback(this[i], i, this)); } } return result; };
for (let i = startIndex; i < this.length; i++) { if (this.hasOwnProperty(i)) { accumulator = callback(accumulator, this[i], i, this); } } return accumulator; };
functionheapSort(arr) { constheapify = (arr, n, i) => { let largest = i; let left = 2 * i + 1; let right = 2 * i + 2; if (left < n && arr[left] > arr[largest]) largest = left; if (right < n && arr[right] > arr[largest]) largest = right; if (largest !== i) { [arr[i], arr[largest]] = [arr[largest], arr[i]]; heapify(arr, n, largest); } };
let n = arr.length; for (let i = Math.floor(n / 2) - 1; i >= 0; i--) { heapify(arr, n, i); } for (let i = n - 1; i > 0; i--) { [arr[0], arr[i]] = [arr[i], arr[0]]; heapify(arr, i, 0); } return arr; }
functionmyInstanceof(obj, constructor) { if (typeof constructor !== 'function') { thrownewTypeError('Right-hand side of instanceof is not callable'); }
if (obj == null) returnfalse; // 处理 null 和 undefined
let proto = Object.getPrototypeOf(obj); while (proto) { if (proto === constructor.prototype) returntrue; proto = Object.getPrototypeOf(proto); }
returnfalse; }
// 测试 try { console.log(myInstanceof([], null)); // 抛出 TypeError } catch (e) { console.error(e.message); // 输出: Right-hand side of instanceof is not callable }
给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
更改 nums 数组,使 nums 的前 k 个元素包含不等于 val 的元素。nums 的其余元素和 nums 的大小并不重要。
返回 k。
用户评测:
评测机将使用以下代码测试您的解决方案:
int[] nums = [...]; // 输入数组
int val = ...; // 要移除的值
int[] expectedNums = [...]; // 长度正确的预期答案。
// 它以不等于 val 的值排序。
int k = removeElement(nums, val); // 调用你的实现
assert k == expectedNums.length;
sort(nums, 0, k); // 排序 nums 的前 k 个元素
for (int i = 0; i < actualLength; i++) {
assert nums[i] == expectedNums[i];
}
如果所有的断言都通过,你的解决方案将会 通过。
示例 1:
输入: nums = [3,2,2,3], val = 3
输出: 2, nums = [2,2,_,_]
解释: 你的函数函数应该返回 k = 2, 并且 nums 中的前两个元素均为 2。
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
示例 2:
输入: nums = [0,1,2,2,3,0,4,2], val = 2
输出: 5, nums = [0,1,4,0,3,_,_,_]
解释: 你的函数应该返回 k = 5,并且 nums 中的前五个元素为 0,0,1,3,4。
注意这五个元素可以任意顺序返回。
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
解答
1 2 3 4 5 6 7 8 9 10
var removeElement = function(nums, val) { let len = nums.length; let k = 0; for(let i = 0; i < len; i++) { if(nums[i] !== val) { nums[k++] = nums[i]; } } return k; };
var rotate = function(nums, k) { k = k % nums.length; let f = nums.slice(0, nums.length - k); let b = nums.slice(nums.length - k); // nums = b.concat(f); nums.splice(0, nums.length, ...b.concat(f)); };
翻转
1 2 3 4 5 6 7 8 9 10 11 12 13 14
var rotate = function(nums, k) { k = k % nums.length; // 防止 k 大于数组长度 nums.reverse(); // 第一步:反转整个数组 reverse(nums, 0, k - 1); // 第二步:反转前 k 个元素 reverse(nums, k, nums.length - 1); // 第三步:反转剩余部分 };
/** * @param {string} S * @return {string[]} */ var permutation = function(S) { // string to array let temp = S.split(''); let len = temp.length; let res = []; dfs(0); return res;
The previous section covered the tokenization steps and conversion from string tokens into integer token IDs in great detail. The next step before we can finally create the embeddings for the LLM is to generate the input-target pairs required for training an LLM. 前一节详细介绍了分词步骤和将字符串词元转换为整数词元ID的过程。在最终为LLM创建嵌入之前,下一步是生成训练LLM所需的输入-目标对。
What do these input-target pairs look like? As we learned in chapter 1, LLMs are pretrained by predicting the next word in a text, as depicted in figure 2.12. 这些输入-目标对是什么样的?正如我们在第1章中学到的,LLM通过预测文本中的下一个单词进行预训练,如图2.12所示。
Figure 2.12 Given a text sample, extract input blocks as subsamples that serve as input to the LLM, and the LLM’s prediction task during training is to predict the next word that follows the input block. During training, we mask out all words that are past the target. Note that the text shown in this figure would undergo tokenization before the LLM can process it; however, this figure omits the tokenization step for clarity. 图2.12 给定一个文本样本,提取输入块作为子样本,作为LLM的输入,LLM在训练期间的预测任务是预测紧跟在输入块后的下一个单词。在训练期间,我们屏蔽了所有超出目标的单词。请注意,图中显示的文本在LLM处理之前会进行分词;然而,为了清晰起见,本图省略了分词步骤。
In this section we implement a data loader that fetches the input-target pairs depicted in Figure 2.12 from the training dataset using a sliding window approach. 在本节中,我们实现了一个数据加载器,该加载器使用滑动窗口方法从训练数据集中获取图2.12中描绘的输入-目标对。
To get started, we will first tokenize the whole The Verdict short story we worked with earlier using the BPE tokenizer introduced in the previous section: 首先,我们将使用上一节介绍的BPE分词器对整个The Verdict短篇小说进行分词:
Executing the code above will return 5145, the total number of tokens in the training set, after applying the BPE tokenizer. 执行上述代码将返回5145,这是应用BPE分词器后的训练集中词元的总数量。
Next, we remove the first 50 tokens from the dataset for demonstration purposes as it results in a slightly more interesting text passage in the next steps: 接下来,我们从数据集中移除前50个词元以进行演示,因为这会在接下来的步骤中生成一个稍微有趣的文本段落:
1
enc_sample = enc_text[50:] # 移除前50个词元
One of the easiest and most intuitive ways to create the input-target pairs for the next-word prediction task is to create two variables, x and y, where x contains the input tokens and y contains the targets, which are the inputs shifted by 1: 创建输入-目标对进行下一个单词预测任务的最简单和最直观的方法之一是创建两个变量,x 和 y,其中 x 包含输入词元,y 包含目标,即输入右移1位:
Processing the inputs along with the targets, which are the inputs shifted by one position, we can then create the next-word prediction tasks depicted earlier in figure 2.12, as follows: 处理包含目标的输入,目标是输入右移一个位置,然后我们可以创建图2.12中所描绘的下一个单词预测任务,如下所示:
Everything left of the arrow (—->) refers to the input an LLM would receive, and the token ID on the right side of the arrow represents the target token ID that the LLM is supposed to predict. 箭头(—->)左边的所有内容表示LLM将接收的输入,箭头右边的词元ID表示LLM应预测的目标词元ID。
For illustration purposes, let’s repeat the previous code but convert the token IDs into text: 为了说明,我们重复前面的代码,但将词元ID转换为文本:
1 2 3 4 5 6 7 8 9
for i inrange(1, context_size+1): # 遍历上下文大小 context = enc_sample[:i] # 获取当前上下文 desired = enc_sample[i] # 获取目标词元 print(tokenizer.decode(context), "---->", tokenizer.decode([desired])) # 打印解码后的上下文和目标 # 下面的输出显示了输入和输出在文本格式中的样子: # and ----> established # and established ----> himself # and established himself ----> in # and established himself in ----> a
The following outputs show how the input and outputs look in text format: 下面的输出显示了输入和输出在文本格式中的样子:
1 2 3 4 5
and ----> established and established ----> himself and established himself ----> in and established himself in ----> a # 我们现在已经创建了输入-目标对,可以将它们用于LLM训练。
We’ve now created the input-target pairs that we can turn into use for the LLM training in upcoming chapters. 我们现在已经创建了输入-目标对,可以将它们用于LLM训练。
There’s only one more task before we can turn the tokens into embeddings, as we mentioned at the beginning of this chapter: implementing an efficient data loader that iterates over the input dataset and returns the inputs and targets as PyTorch tensors, which can be thought of as multidimensional arrays. 在我们将词元转换为嵌入之前,还有最后一个任务:实现一个高效的数据加载器,它遍历输入数据集并将输入和目标作为PyTorch张量返回,可以将其视为多维数组。
In particular, we are interested in returning two tensors: an input tensor containing the text that the LLM sees and a target tensor that includes the targets for the LLM to predict, as depicted in Figure 2.13.
Figure 2.13 To implement efficient data loaders, we collect the inputs in a tensor, x, where each row represents one input context. A second tensor, y, contains the corresponding prediction targets (next words), which are created by shifting the input by one position.
While Figure 2.13 shows the tokens in string format for illustration purposes, the code implementation will operate on token IDs directly since the encode method of the BPE tokenizer performs both tokenization and conversion into token IDs as a single step.
For the efficient data loader implementation, we will use PyTorch’s built-in Dataset and DataLoader classes. For additional information and guidance on installing PyTorch, please see section A.1.3, Installing PyTorch, in Appendix A.
The GPTDatasetV1 class in listing 2.5 is based on the PyTorch Dataset class and defines how individual rows are fetched from the dataset, where each row consists of a number of token IDs (based on a max_length) assigned to an input_chunk tensor. The target_chunk tensor contains the corresponding targets. I recommend reading on to see how the data returned from this dataset looks like when we combine the dataset with a PyTorch DataLoader – this will bring additional intuition and clarity.
If you are new to the structure of PyTorch Dataset classes, such as shown in listing 2.5, please read section A.6, Setting up efficient data loaders, in Appendix A, which explains the general structure and usage of PyTorch Dataset and DataLoader classes.
Let’s test the dataloader with a batch size of 1 for an LLM with a context size of 4 to develop an intuition of how the GPTDatasetV1 class from listing 2.5 and the create_dataloader_v1 function from listing 2.6 work together:
The first_batch variable contains two tensors: the first tensor stores the input token IDs, and the second tensor stores the target token IDs. Since the max_length is set to 4, each of the two tensors contains 4 token IDs. Note that an input size of 4 is relatively small and only chosen for illustration purposes. It is common to train LLMs with input sizes of at least 256.
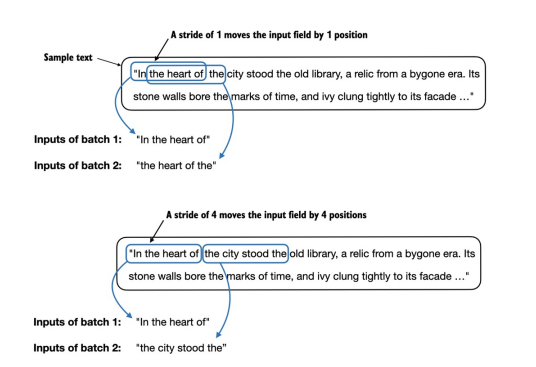
If we compare the first with the second batch, we can see that the second batch’s token IDs are shifted by one position compared to the first batch (for example, the second ID in the first batch’s input is 367, which is the first ID of the second batch’s input). The stride setting dictates the number of positions the inputs shift across batches, emulating a sliding window approach, as demonstrated in Figure 2.14.
Figure 2.14 When creating multiple batches from the input dataset, we slide an input window across the text. If the stride is set to 1, we shift the input window by 1 position when creating the next batch. If we set the stride equal to the input window size, we can prevent overlaps between the batches.
EXERCISE 2.2 DATA LOADERS WITH DIFFERENT STRIDES AND CONTEXT SIZES 练习 2.2 具有不同stride和context大小的数据加载器
To develop more intuition for how the data loader works, try to run it with different settings such as max_length=2 and stride=2 and max_length=8 and stride=2.
Batch sizes of 1, such as we have sampled from the data loader so far, are useful for illustration purposes. If you have previous experience with deep learning, you may know that small batch sizes require less memory during training but lead to more noisy model updates. Just like in regular deep learning, the batch size is a trade-off and hyperparameter to experiment with when training LLMs.
Before we move on to the two final sections of this chapter that are focused on creating the embedding vectors from the token IDs, let’s have a brief look at how
we can use the data loader to sample with a batch size greater than 1:
Note that we increase the stride to 4. This is to utilize the data set fully (we don’t skip a single word) but also avoid any overlap between the batches, since more overlap could lead to increased overfitting.
In the final two sections of this chapter, we will implement embedding layers that convert the token IDs into continuous vector representations, which serve as input data format for LLMs.
voidquick_sort(int q[],int l,int r) { if(l>=r) return; int i = l-1; int j = r+1; int x = q[(l+r)/2]; while(i<j){ do i++; while(q[i]<x); do j--; while(q[j]>x); if(i<j) swap(q[i],q[j]); } quick_sort(q,l,j); quick_sort(q,j+1,r); }
vector<int> div(vector<int> &A, int b ,int &r){ vector<int> C;// 商 r = 0;// 余数 // 从最高位开始算--不同于其他几种计算 for(int i = A.size() - 1;i >= 0 ; i--){ r = r * 10 + A[i]; C.push_back(r / b); r %= b; } reverse(C.begin() ,C.end()); while(C.size()>1 && C.back()==0) C.pop_back(); // 去除前导0 return C; }
intmain() { string a; int b; vector<int> A; cin>>a>>b; for(int i = a.size()-1;i>=0;i--){ A.push_back(a[i]-'0'); } int r; auto C = div(A,b,r); for(int i = C.size()-1;i>=0;i--){ printf("%d",C[i]); } cout<<endl; cout<<r<<endl; }
// 二分求出x对应的离散化的值 intfind(int x)// 找到第一个大于等于x的位置 { int l = 0, r = alls.size() - 1; while (l < r) { int mid = l + r >> 1; if (alls[mid] >= x) r = mid; else l = mid + 1; } return r + 1; // 映射到1, 2, ...n }
802.区间和 难☹️
假定有一个无限长的数轴,数轴上每个坐标上的数都是 0 现在,我们首先进行 n 次操作,每次操作将某一位置 x 上的数加 c 接下来,进行 m 次询问,每个询问包含两个整数 l 和 r,你需要求出在区间 [l,r] 之间的所有数的和
输入格式
第一行包含两个整数 n 和 m 接下来 n 行,每行包含两个整数 x 和 再接下来 m 行,每行包含两个整数 l 和 r
int st = -2e9, ed = -2e9; for (auto seg : segs) if (ed < seg.first) { if (st != -2e9) res.push_back({st, ed}); st = seg.first, ed = seg.second; } else ed = max(ed, seg.second);
if (st != -2e9) res.push_back({st, ed});
segs = res; }
803. 区间合并
给定 n 个区间 [li,ri],要求合并所有有交集的区间。 注意如果在端点处相交,也算有交集。 输出合并完成后的区间个数。
// returns the view matrix calculated using Euler Angles and the LookAt Matrix glm::mat4 GetViewMatrix() { return glm::lookAt(Position, Position + Front, Up); } };
ProcessKeyboard处理从任何类似键盘的输入系统接收的输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidProcessKeyboard(Camera_Movement direction, float deltaTime) { float velocity = MovementSpeed * deltaTime; if (direction == FORWARD) Position += Front * velocity; if (direction == BACKWARD) Position -= Front * velocity; if (direction == LEFT) Position -= Right * velocity; if (direction == RIGHT) Position += Right * velocity; if (direction == DOWN) Position -= Up * velocity; if (direction == UP) Position += Up * velocity; }
// make sure that when pitch is out of bounds, screen doesn't get flipped if (constrainPitch) { if (Pitch > 89.0f) Pitch = 89.0f; if (Pitch < -89.0f) Pitch = -89.0f; }
// update Front, Right and Up Vectors using the updated Euler angles updateCameraVectors(); }
voidupdateCameraVectors() { // calculate the new Front vector glm::vec3 front; front.x = cos(glm::radians(Yaw)) * cos(glm::radians(Pitch)); front.y = sin(glm::radians(Pitch)); front.z = sin(glm::radians(Yaw)) * cos(glm::radians(Pitch)); Front = glm::normalize(front); // also re-calculate the Right and Up vector Right = glm::normalize(glm::cross(Front, WorldUp)); Up = glm::normalize(glm::cross(Right, Front)); }
// tell GLFW to capture our mouse glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED);
// glad: load all OpenGL function pointers // --------------------------------------- if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) { std::cout << "Failed to initialize GLAD" << std::endl; return-1; } // configure global opengl state // ----------------------------- glEnable(GL_DEPTH_TEST);
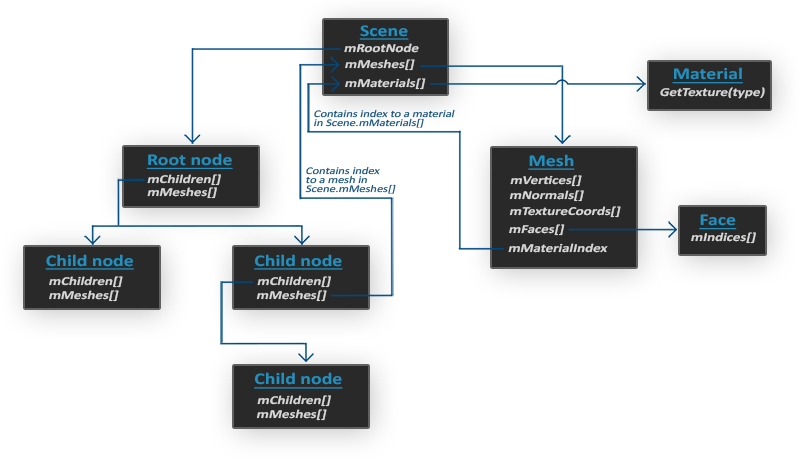
structVertex { // position glm::vec3 Position; // normal 法线 glm::vec3 Normal; // texCoords glm::vec2 TexCoords; // tangent 切线 glm::vec3 Tangent; // bitangent 双切线 glm::vec3 Bitangent; //bone indexes which will influence this vertex int m_BoneIDs[MAX_BONE_INFLUENCE]; //weights from each bone float m_Weights[MAX_BONE_INFLUENCE]; };
// returns the view matrix calculated using Euler Angles and the LookAt Matrix glm::mat4 GetViewMatrix() { return glm::lookAt(Position, Position + Front, Up); } };
ProcessKeyboard处理从任何类似键盘的输入系统接收的输入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidProcessKeyboard(Camera_Movement direction, float deltaTime) { float velocity = MovementSpeed * deltaTime; if (direction == FORWARD) Position += Front * velocity; if (direction == BACKWARD) Position -= Front * velocity; if (direction == LEFT) Position -= Right * velocity; if (direction == RIGHT) Position += Right * velocity; if (direction == DOWN) Position -= Up * velocity; if (direction == UP) Position += Up * velocity; }
// make sure that when pitch is out of bounds, screen doesn't get flipped if (constrainPitch) { if (Pitch > 89.0f) Pitch = 89.0f; if (Pitch < -89.0f) Pitch = -89.0f; }
// update Front, Right and Up Vectors using the updated Euler angles updateCameraVectors(); }
voidupdateCameraVectors() { // calculate the new Front vector glm::vec3 front; front.x = cos(glm::radians(Yaw)) * cos(glm::radians(Pitch)); front.y = sin(glm::radians(Pitch)); front.z = sin(glm::radians(Yaw)) * cos(glm::radians(Pitch)); Front = glm::normalize(front); // also re-calculate the Right and Up vector Right = glm::normalize(glm::cross(Front, WorldUp)); Up = glm::normalize(glm::cross(Right, Front)); }
// render the loaded model glm::mat4 model = glm::mat4(1.0f); model = glm::translate(model, glm::vec3(0.0f, 0.0f, 0.0f)); // translate it down so it's at the center of the scene model = glm::scale(model, glm::vec3(1.0f, 1.0f, 1.0f)); // it's a bit too big for our scene, so scale it down ourShader.setMat4("model", model); ourModel.Draw(ourShader); // ourModel2.Draw(ourShader); // ourModel3.Draw(ourShader);
//-- lightCubeShader.use(); lightCubeShader.setMat4("projection", projection); lightCubeShader.setMat4("view", view); model = glm::mat4(1.0f); model = glm::translate(model, lightPos); model = glm::scale(model, glm::vec3(0.2f)); // a smaller cube lightCubeShader.setMat4("model", model); //--
// glfw: swap buffers and poll IO events (keys pressed/released, mouse moved etc.) // ------------------------------------------------------------------------------- glfwSwapBuffers(window); glfwPollEvents(); }




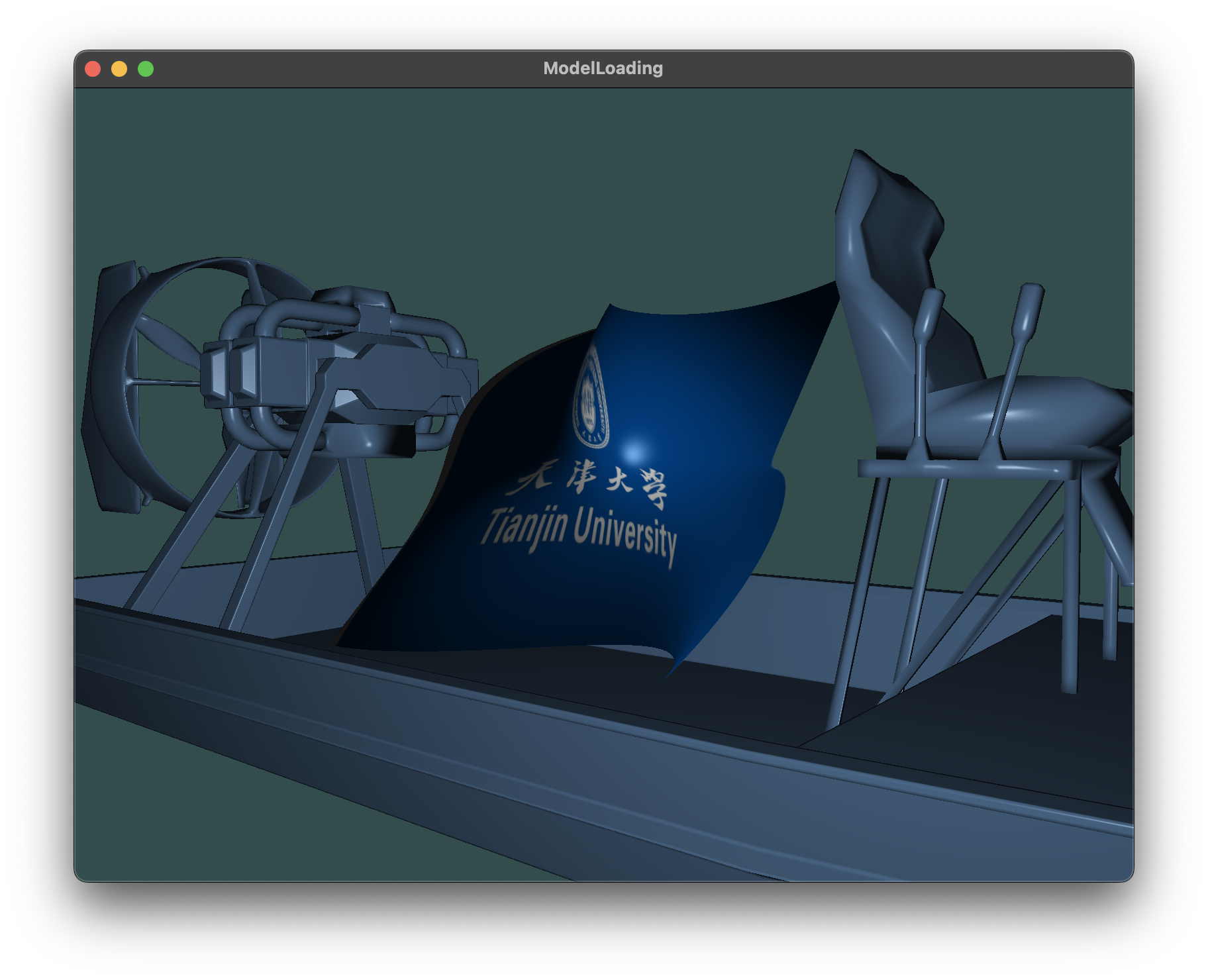
 ##### 向前
##### 向前
 ##### 向后
##### 向后
 ##### 向上
##### 向上
 ##### 旋转
##### 旋转