Learning "Build a Large Language Model (From Scratch)"
阅读量:
次
文章字数:
1.3k字
阅读时长:
5分钟
学习《Build a Large Language Model (From Scratch)》一书
《Build a Large Language Model (From Scratch)》
- Author: Sebastian Raschka
- BOOK: Build a Large Language Model (From Scratch)
- GitHub: rasbt/LLMs-from-scratch
- 中英文pdf版本, 可联系我获取
- 如有侵权,请联系删除
Setup
参考
setup/01_optional-python-setup-preferences.setup/02_installing-python-libraries
按照步骤配置环境:
1 | git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git |
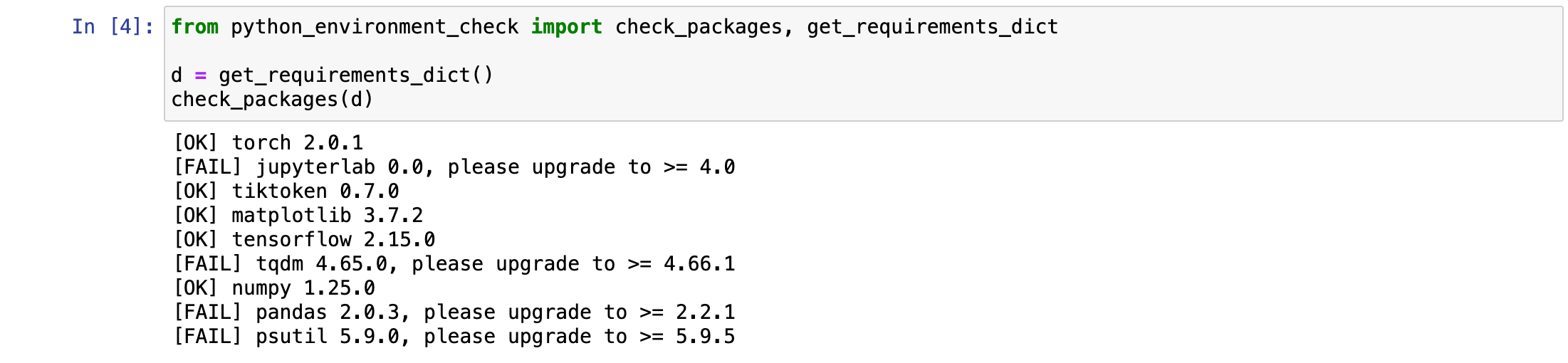
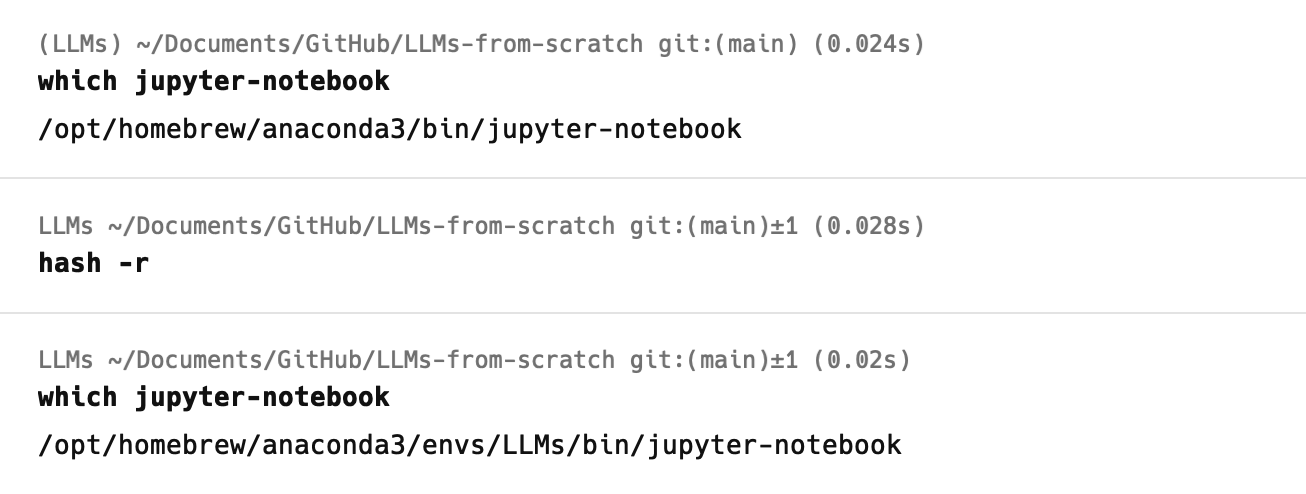
在这里遇到了以下问题:
解决方案:
1 | hash -r |
解释:
hash是一个 Bash 内建命令,用于查找并记住命令的位置。如果你在安装了新的软件之后,想要立即使用它,但是 Bash 仍然使用旧的命令,那么你可以使用hash -r命令来刷新 Bash 的命令缓存。
Chapter 01
Chapter 02
目录:
- 2.1 Understanding word embeddings
- 2.2 Tokenizing text
- 2.3 Converting tokens into token IDs
- 2.4 Adding special context tokens
- 2.5 Byte pair encoding
- 2.6 Data sampling with a sliding window
- 2.7 Creating token embeddings
- 2.8 Encoding word positions
- 2.9 Summary